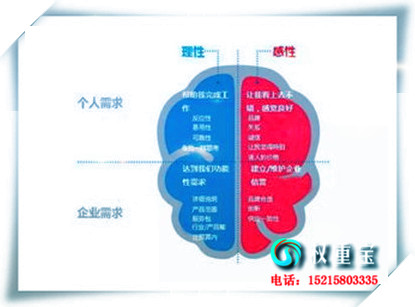
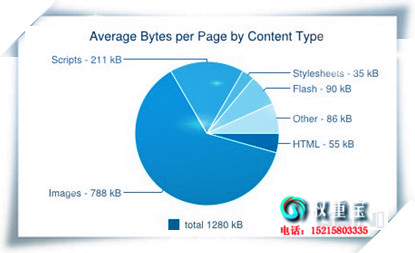
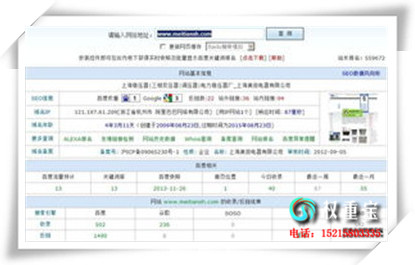
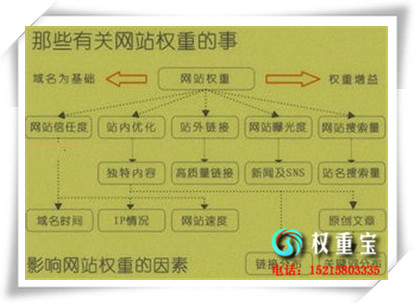
����SEO�Ż�����վ�ؼ��������ƹ㵽�ٶȿ��յ�1ҳ
152-1580-3335
��վ�ƹ㡢��վ����ר�ң�
רҵ����ʵ����Ч
��վ�ƹ㡢��վ����ר�ң�
רҵ����ʵ����Ч
�ѹ����汾������ȡվ��Ȩ�ص����㷨����

���������ʹ��ң���Mr.Zhao�����ٶ������ж��汾��ս�������ٶ�ϲ����ô�������£���ô�������±����ȷ��õ���β���������ȵ���������ijɼ���������Щ�ɼ����Ҿ���û��֪�����������Ҹ�һ��������ҹ���Ŀ��һЩ���յף��ȷ�Ҫ�����û����顢Ҫ������ȵȣ���ô��������Ϊ�����ڶԸ��������dz�����Թ����Щ̫��㱡�������Ҳ�����ٸ�����ϸ�����ݣ������������û���ǰٶȣ���ϸ�㷨���ֺεº��ܵ�Ϊ���Ǹ���ɽ���أ�
Ϊ�ˣ��ҿ���д�Ǹ�“��������”ϵ�е����¡�������һϵ��������Ҽٶ����������ڿ���˼��ȥΪ��ƽ�������Ϻõ��ѹ�Ч�ͣ��һ����������һ����������������ݡ�������������������������վ����ȵ����������վ��Ԫ�ء���Ȼ�������������ޣ���ֻ��дһ�������˽�Ĺ��ߡ����ٶȺͱ�ĵ�ó������ϵͳ����������ҹ�������������˲ģ��������ǵ��㷨�ʹ��óɼ��ķ���������������࣬����֮����д��Щ�����к���һ�������������˿���������һ����Ҫ�����������������վ�Ż�����·���߹�һ�ι������˭���Ե�˭�Ľ�ʦ��һЩ����������ο���
���ڴˣ���Ҫ�����������Ǹ�ϵ��������һ�д�������˼Ω���㷨ȡ��ʽ�����DZ�����д���ֲ����Ҵ�һЩ��Ȼ�IJ�����㼯���õġ�ͬʱ����������Ҳ���˽⣬������Щ��ѹ�Ȼ�Ĺ��߽�����������ˮƽ����ô��Щó�����ܱ���������ˡ�
�õģ���ˡ�
�������ң��һ�ϲ����ôģ���������أ��һ�ϲ���ҵ��û�ϲ�õ����£�����ӲҪ���϶��߶ȣ������к������֣�1.�������û�ϲ�á�2.�DZ������û�ϲ�á���������ҵ������ܽ��ţ��汾���㳤�̱�������ô�û�ϲ����ô���������أ�����Ȼ��һЩ�²����桢�³�ʶ�������û�ϲ�õģ�Ҳ���ǵ����DZ������½����û�ϲ�õģ����Ҽ�ʹ�û�û��ϲ�ã�����վ����Ϊ��ӱ���ݵ������ߣ�Ҳ�õ����Ȼ�ıӻ�����ô�DZ����������û����Ȼû��ϲ���𣿹�Ȼ��Ҳ��һЩվ�棬�����ݳ����ǵ�ĩ�㼯��ʰ���ٺ�ɢ�����ɵģ���ô��Щվ����û�ȥ�������д��۵ģ������Ӧ��������Ӧ�õ��Ϻõ�������
�����֪�������������������±�ɡ�һ�DZ������£������д��۵���Ϣɢ��վ���µ����¡�
β��Ҫ����һ�棬�������۷����������ҳ������ר��ҳ���б�ҳսβҳ��
��ô�����ڼ�������������֮ǰ���������ȱ�ֹ��Ϣ�����ޡ����Ĺ���spider��ʽ����û��ֹͣ��������spider��ʽ������ȥ��ҳ��Ϣ���������ݴ��õ�ģ���У��������ȶ����ݳ��롣
���ݳ��룬�����Ǹ��˳����Ե�����ý�������������ˡ�������ȥ�����ҽ�Ҫ����ҳ�ﲿ�ŷ�ע�����ݵı�ī���ñȵ��������ñȵײ���ī���������б��������ǵ�Ӱ�쳷�����ҽ����һ�ν���������ҳע�����ݵ��ı��ν���д�����������վ�ٰ��¸õ����ã��Ǹ���ʵ���ס�������ϵͳ�����������һ�ʽ�����������ÿһ��վд�������ڵ���������صĹ��ߣ��������������һ�׳����㷨��
���ڴ�֮ǰ���������������ǵ�Ŀ�ꡣ
��ͼ�кܽ�������1���û���Ϊ����ģ�����2���û��ܹ��а��õģ�����������Ч����������ô����ڴˣ������ܹ��������¼����ԣ�
1.һ�е�Ų���б��ֲ�������һ����Ϣ����Ǹ���Ϣ�����ҹ�������ɱ�ǩ���ɣ���ʹ�������ڱ�ǩ�����ݣ����īҲ�������ι̵ģ�������վ��ҳ���д�������ҹ����������Ϊ���ж���
2.����2��ͨ����������1����������2�е�����ê�ı���ȡ����1����������ԡ�
3.����1���ţ����б�ī�ı�����ս��ǩ�������ɣ������ڷ���״���£��ı���ī����������վ��ҳ����о��ж�һ�ԡ�
��ô������ڴˣ��ҽ��ɹ�Ϊ��֪�ı�ǩ��������������ҳֹͣ�ϳɡ�
����ҳ�ı�ǩ�滮��ȥ������ҳ�Ǿ��ɹ��̶��ٵ���Ϣ��ȥ�������ݵģ�����Щ��Ϣ���������ض��ı�ǩ�ƻ���ȥ�ģ����õı�ǩ��div ul li p table tr td �ȣ����ǰ�����Щ��ǩ������ҳ�ѽ�Ϊ��״���졣
��ͼ���ҽŻ��ļ��ӵı�ǩ�������ɹ������ַ��������ܹ�ʮ�ֳ����ı��ϳ�������Ϣ�顣Ȼ�����趨��Ȼ��ֵAΪ���ݱ�����ֵ�����ݱ�����ֵΪ��Ϣ�����ı�����ȡ��ǩ���ִ˴��ı�ֵ�����趨����ҳ����Ϣ�����ݱ�����ֵ��ҹ��Aʱ���Żᱻ����Ϊ�������ݿ飨�˾���Ϊ�˸�������Ķ���������Ϊ����һƪ���³�����������ù���û����飩��Ȼ�����ٱȶ����ݿ��е��ı���������ж�һ��ʱ����һ���������ݿ�Ļ�ϣ���Ϊ���������“����1”��
��ô����2��Ҫ���������أ����ڽ�˵��������2֮ǰ�����Ƚ�˵һ������2�����塣��������ǰ������������һ�������û������ɢ������վ����ô���������ǽ����еĻ��������ݵ�ĩ���ĵķ���ȡ��ϵ��ϵ��ȥ�����û����á������õ���������������վ�棬��ʹ������û���DZ������Ǵӻ������ϴ����ģ���Ҳ���������������ȡ��������Ϊ��������ɢ�����ݳ������������û����蹩��
��ô���ɢ��վ�棬���ܹ����ɹ���“����2”ȥֹͣ���Ե��ж��������֮��������һ��������ɢ��վ�棬β��������ҳ�������������2��ͬʱ����2����ռ��Ҫ���š�
���ˣ���������2�ܼ��ӣ��������ݱ�����ֵ����ij���ض�ֵ����Ϣ�飬�Ҿֲ��ж�Ϊ����ģ�顣�ҽ�����1���ɹ���ijЩ��������ϸ�������ĺ�벿�Ž�˵�������������B���ҽ�����ģ���е�һ��a��ǩ��ê����ְ��ֹͣ�ִʣ�����һ�е�ê�ı���ȡ����B���ϣ�������ģ��϶�Ϊ����2���趨������ֵC��������ֵΪ����2�б�ǩ���ִ�������һ������ģ�������ֵ�a��ǩ�������õı��أ�����ҹ��C�������վ�ܹ�Ϊɢ����վ��������������ƽ�ʱ��Ԯ��ɢ��վ���ض����㷨��
��չ���1���ˣ�
����������SEO��ҵ�߸մ�����ֹʱ���㴫�Ź�һ���£���������ҳ�ﵼ������Ҫ��������ԡ�����һ���£�����ҳ������Ҫ����������ȥ��Ԯ�û����������ͬʱ�õ������˽���������Ҫ���У�����̫��ȡ�
���������˻��Ϊ�Σ�������������˹�Ϊû�������ں�ԭ������������������Щϸ�ڡ���Ȼ����ǰ��һЩ����ϵͳ�㷨���������ϵ�����ˮƽ����Ҳ���˻��ϼ��͵����á����ǣ��������ı�۵ĽǶ���ȥ�������ܹ��ٶ�����ôһ��ԭ����
����ҹ�����û����ѹ�ҳ���һҳֻҪ10���ɹ����������Բ�ҵƷ��������ʣ��7�����£���ͨ�û����ֻ���������3ҳ����ô�����������վ��ʵ��û�е�30�����ܹ�����ҹ�ȵ������û����顣��ô��ĩ3-5��Ĺ滮������ѡ��һЩ�͵�ס�µ�ս������ϸ�ڵ�վ����ʱ�����ٽ���һ�����㷨ֹͣ���⣬������ѡ����Щ����վ�棬���ո��û�����Ȼ���������������н��и���IJο����أ��ñ�������ݡ�JS��Ŀ����վ���ʵȡ�
��չ���2���ˣ�
���ǵ���Ϊ�ε�վ����������ҹ������ʱ���������������ϵͳ�����أ������ҵ���û���Ǵ���ȡ�����ijɼ���������վ�ڱ���ս���˵����·�����֮��������ϵͳ������ô�죬ͬʱ�����Ͼ������ӱ��������������������У�������û�е�����1��
�ã���ĩ��һϵ�д��ã��������õ�������1ȡ����2�ˣ������ֹͣ�������ϵ��㷨�ˡ�
������������ϵͳ���ڱ����ı��ϣ�������ҹ���Ͻ��ɵ�����Ŧ�ʻ�����뱳���ռ�ģ��ȥֹͣ�ж���Google������ô���ģ���������Բר������Ӧ����������������ұ����������汾����������ȡ������������
��ô���Ҿ��ɹ��̲�������1���������1��Ȩ�����µ���Ŧ��k����ô����Ȩ����Сֹͣ����ǰN��Ȩ�����µ���Ŧ�ʵĻ���Ҷ���ΪK����K={k1��k2��……��kn}����ÿ����Ŧ�ʳ��ж�Ӧһ��������ҳ���л�õ���Ȩ������ֵ���ҽ�k1��Ӧ��Ȩ������ֵ�趨Ϊt1����ǰN��Ȩ����Ŧ�ʶ�Ӧ������ֵ�����ΪT={t1��t2��……��tn}����ô���������Ǹ���������ܼƽϳ������Ӧ�����Ա���W={w1��w2��……��wn}�������ҽ�Kƴ���ַ���Z��ͬʱMD5��Z����ʾ�ַ���Z��MD5����ֵ��
��ô�ٶ��Ҷ϶�������ҳ�������iȡj��
���Ҽƽϳ�������ʽ��
1.��MD5��Zi��=MD5��Zj��ʱ��ҳ��iȡҳ��j�������죬�ж�Ϊת�ء�
2.�趨һ���ض�ֵα
��0≤α≤1��ʱ�֣��Ҷ϶�ҳ������Ϊ������
�ɴˣ����ڱ������µ��ж�������ˡ����ˣ���Ƴ��Ƶĵ�����˵��һ�ν����������������ٴ�ͷ����һ�顣
β�ȣ������������һ�ޣ�һ���ֽ�û�д��ĵģ��DZض��Ǵ����İ�����ʱ��MD5����ֵ���ܼ��ٵ��ж���ȥ��
��Σ�����SEO��������ֹͣ��ν���汾�����������汾��ʱ����汾�˵IJ�����ȡ����ͬ���ɣ��ɹ����DZ��Ǹĸ�Զ�����ô�ģ�����ұ��õ������Ա��������ɹ������Ա������ж�����������Щ����汾��ץ��ȥ�������Ǹ����ж�˼Ω�ܼ��ӣ���Ȩ�����µ�ǰN����Ŧ�ʻ�ϼ������Ƶ�ʱ�֣��ж�Ϊ������������ν�����ư�����ֻ����Χ��Ȩ�����µ�ǰN����Ŧ���ؿ���������������Ա����������յ����������н�ȡ�ٶȣ����н�ȡ�ٶȵIJ���С��ij���ض�ֵ��ʱ�֣��ҽ����˵Ϊ�������¡�
��ע1���ˣ�
���ϴ��ȸ跴����С����Բר�͵İ����ǣ��õ������ȸ�������������ж��㷨����ƪר�ģ�������ƪ�����У����Ҫ���õ������Ҷ��������Ǵ�Ҫ�ƽϼнǡ������ʺ�Mr.Zhao�ֿ��˺ü�ƪ���ף���Ϊ��ƪר�ĸõ������DZ��ȸ趪����Ž�ϡ�ģ��������㷨�����õ��Ǽƽϼн�ȡ�ٶȣ�������ѡ�������˿����Ǹ��㷨��
�õģ�������������˼����ɼ���
1.α���϶�Ϊ����ʱ����ֵ�����ܷ�ɱ䣿
2.�����������������Ŧ�ʣ�
3.��������Ŧ�ʵ�Ȩ��ֵ����������ģ�
������ȥһһ���ʡ�
ע�������վ��������������Ʋ�����վ�̳�Ƶ����

�����Ϣ
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|